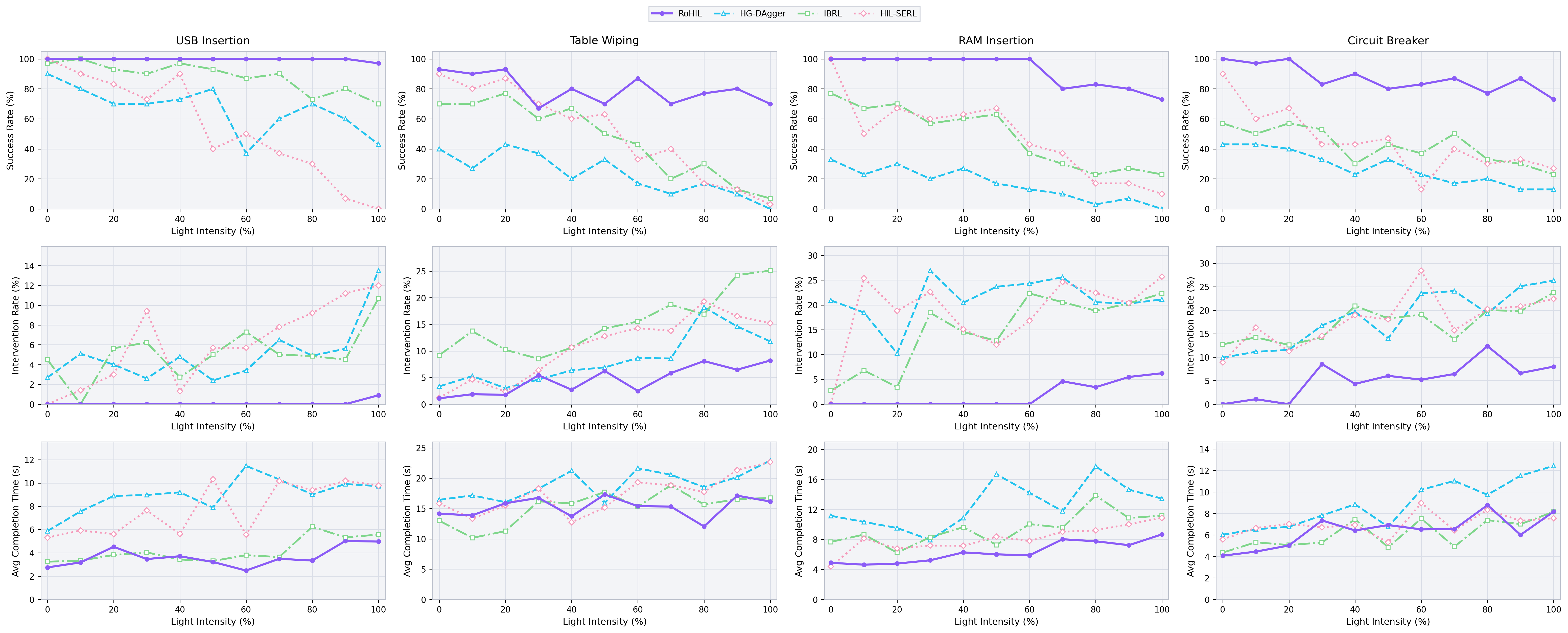
Three Stages: Relight, Retain, Anchor
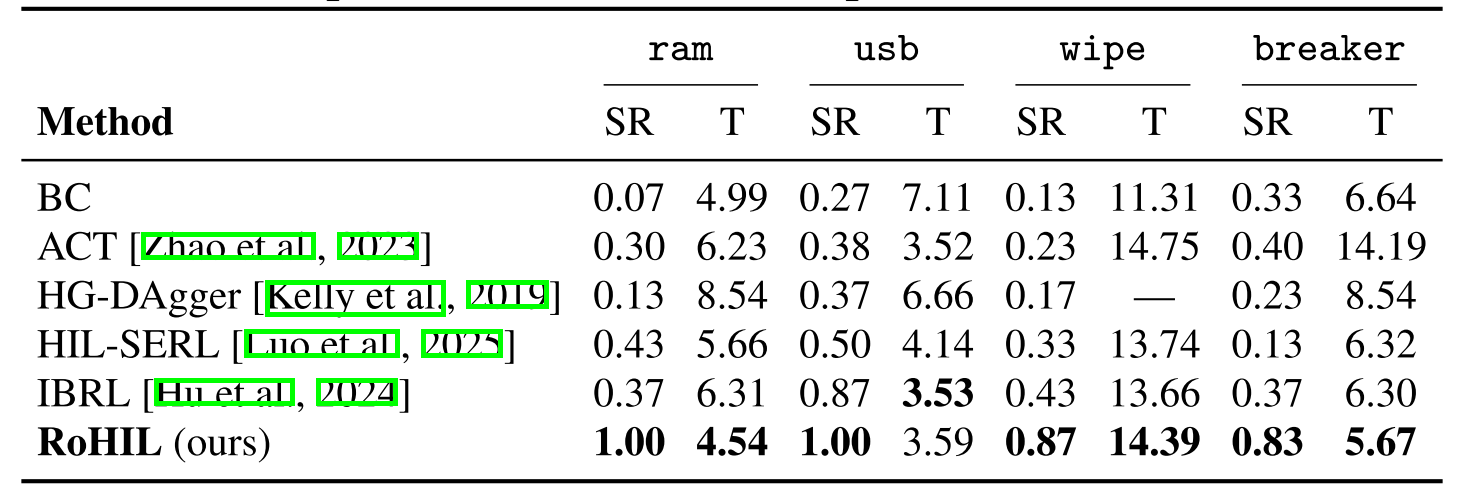
Starting from an online-best HIL-SERL policy that degrades under lighting shifts, RoHIL runs an offline robust fine-tune in three coupled stages. The visual encoder is exposed to illumination-diverse evidence via world-model relighting, while replay-buffer balancing and frozen-source anchors jointly suppress source-domain forgetting at the data, representation, and policy levels.
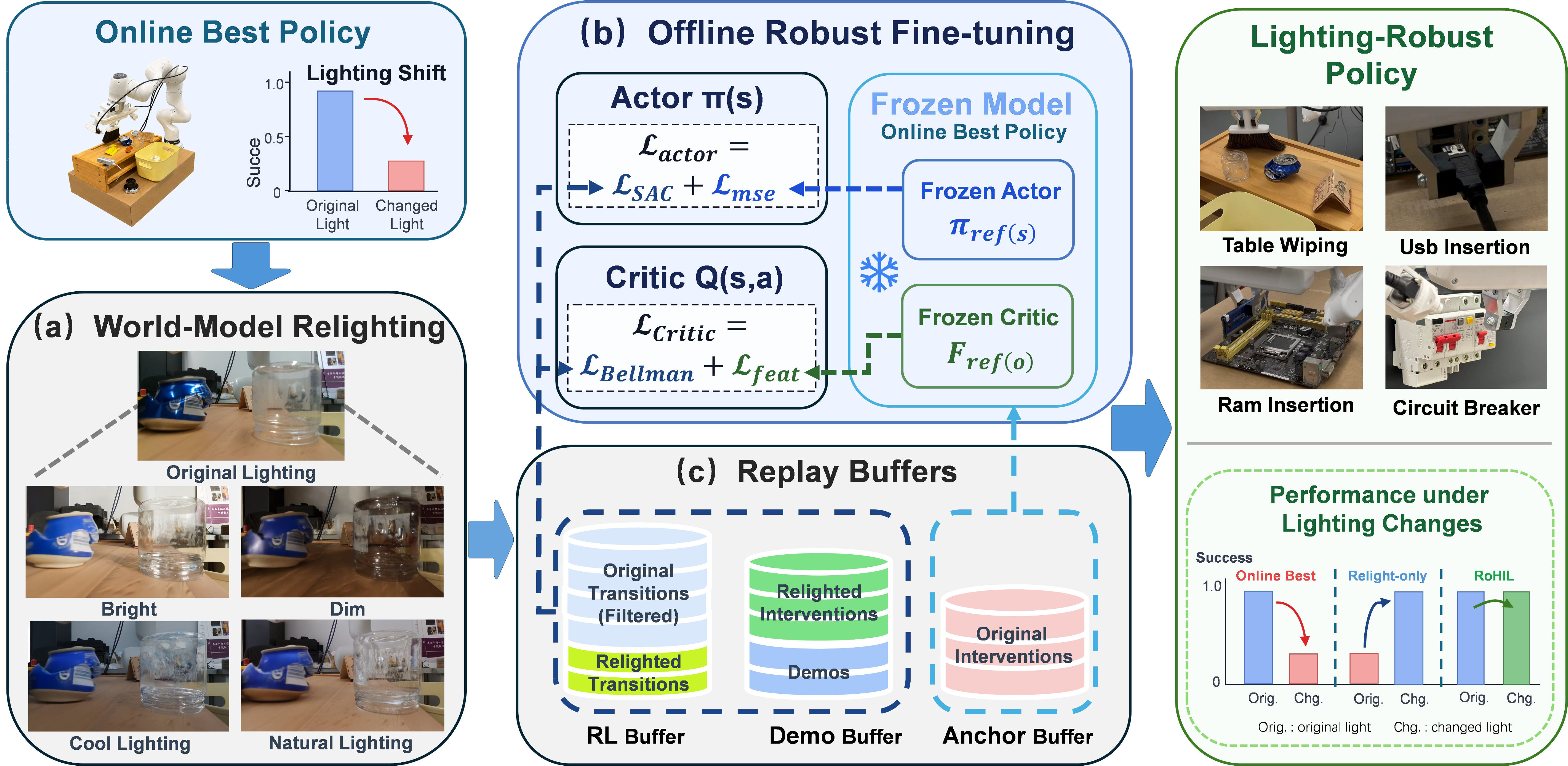
RoHIL overview. (a) A world-model relighter re-synthesises the visual stream of source trajectories under multiple HDRI environments while preserving actions and rewards. (b) Offline robust fine-tune with critic Lcritic = LBellman + Lfeat and actor Lactor = LSAC + Lmse, anchored on a frozen source policy. (c) Illumination-Retention Replay buffers interleave relit adaptation and original-light retention transitions to preserve source-workstation Bellman coverage.
World-Model Relighting
A diffusion-based HDRI-conditioned video relighter re-illuminates recorded RGB streams under four virtual lighting environments. Actions, rewards, and termination labels stay real; only the visual stream changes — giving illumination-diverse observations from a single source-workstation collection.
Illumination-Retention Replay
IRR keeps the RLPD 50/50 demo/RL split but inserts a retention coefficient α: the RL half mixes original-light and relit transitions, preserving Bellman coverage of the source workstation while supplying illumination-adaptation signal. Sweep identifies α = 0.75 as the joint optimum.
Anchored Bellman–Actor Regulariser
A frozen-source feature anchor (Lfeat) constrains visual-encoder drift, while a reference-action mean anchor (Lmse) regularises actor pre-tanh means on expert states. Both anchors decay with training to allow late-stage plasticity.